Aplikacja redaktora systemu dLibra umożliwia importowanie metadanych obiektu z pliku CSV. W tym celu należy utworzyć nowy plik z rozszerzeniem CSV, np. za pośrednictwem programu MS Excel.
Jeśli metadane obiektu mają być importowane dla większej liczby języków (np. polskiego, angielskiego, czy uniwersalnego), plik powinien mieć strukturę taką jak zaprezentowano na poniższym rysunku:
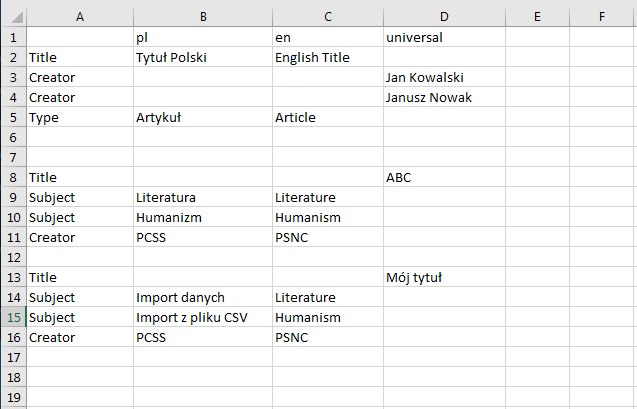
W pliku pierwsza kolumna zawiera nazwy RDF poszczególnych pól metadanych (nazwy RDF można zobaczyć w Aplikacji Redaktora i Administratora systemu dLibra). W kolejnych kolumnach znajdują się wartości przypisane do pól w odpowiednim języku. Na przykładzie druga kolumna zawiera wartości w języku polskim, trzecia w języku angielskim, a czwarta w języku uniwersalnym.
W jednym pliku może znajdować się kilka opisów obiektów, przy czym każdy opis obiektu powinien być oddzielony co najmniej jednym pustym wierszem. W przykładzie pokazano trzy niezależne opisy. Pierwszy opis zawiera wypełnione wartości dla pól: Tytuł (nazwa RDF "Title", wprowadzone dwie wartości - jedna w języku polskim "Tytuł Polski" i jedna w angielskim "English Title"), Twórca (nazwa RDF "Creator", wprowadzone dwie wartości dla języka uniwersalnego "Jan Kowalski" i "Janusz Nowak" - dwa wiersze oznaczone nazwą RDF "Creator"), Typ (nazwa RDF "Type", wprowadzone wartości - jedna w języku polskim "Artykuł" i jedna w angielskim "Article").
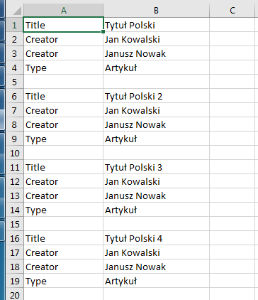
Jeśli importowane będą jedynie metadane w języku polskim, plik może mieć poniższą strukturę (bez konieczności wprowadzania nazw kolumn dla poszczególnych języków, ponieważ jest tylko jeden wypełniany język). Tu również należy rozdzielić informacje o poszczególnych obiektach pustym wierszem:
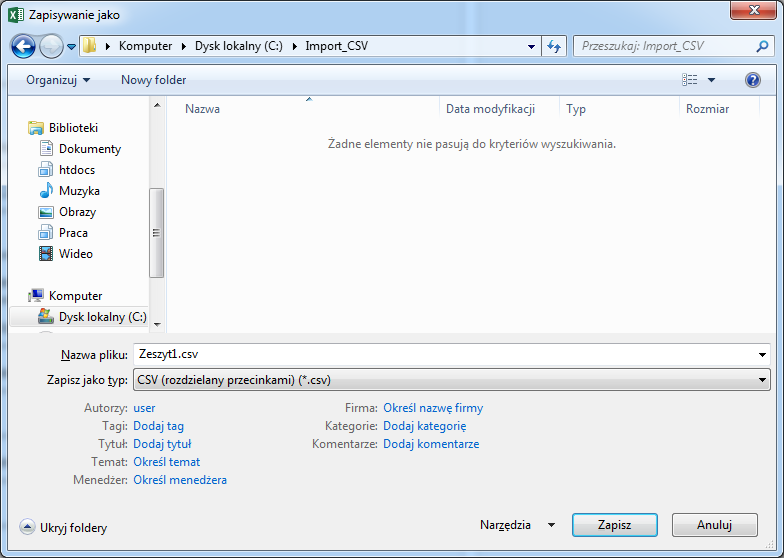
Po utworzeniu nowego pliku, należy zapisać go pod dowolną nazwą na dysku lokalnym komputera, wybierając odpowiedni typ pliku - Zapisz jako typ: CVS (rozdzielany przecinkami)(*.csv). Ekran poniżej przedstawia okno zapisywania pliku dla programu MS Excel.
Plik przygotowany w MS Excel zapisany będzie z użyciem kodowania ANSI, z kolei Aplikacja Redaktora domyślnie pracuje w kodowaniu UTF-8. Dlatego też, aby poprawnie wczytać metadane z plików zapisanych z wykorzystaniem programu MS Excel, należy wprowadzić zmianę w konfiguracji Aplikacji Redaktora. Opis możliwości konfiguracyjnych dostępny jest w dokumentacji Aplikacji Redaktora i Administratora, w sekcji dotyczącej konfiguracji aplikacji. W kontekście mechanizmu importu metadanych z CSV należy wprowadzić następującą konfigurację (linię) w pliku generalConfig.properties:
metadata.csv.encoding = Windows-1250
Jeśli tego nie zrobimy to pliki CSV będą importowane z wykorzystaniem kodowania UTF-8 (domyślne kodowanie używane w Aplikacji Redaktora i Administratora).
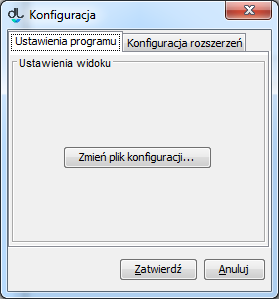
Aby wczytać tak zmodyfikowany plik konfiguracyjny, z menu aplikacji redaktora należy wybrać opcję "Program", a następnie "Konfiguracja".

W nowym oknie należy kliknąć przycisk „Zmień plik konfiguracyjny” i wskazać lokalizację nowego pliku generalConfig.properties.
Po zatwierdzeniu zmian, zaimportowane dane zawierające polskie znaki diakrytyczne, będą widoczne w poprawny sposób.
Import metadanych z pliku CSV możliwy jest z poziomu edytora opisu bibliograficznego (ekran poniżej), który pojawia się, np. w kreatorze nowego obiektu cyfrowego (krok drugi) lub kreatorze planowanego obiektu (krok pierwszy).
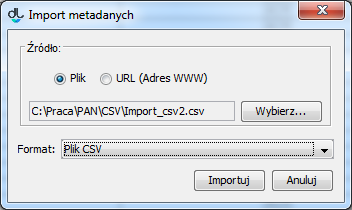
Aby zaimportować opis z poziomu edytora opisu bibliograficznego, należy wybrać znajdujący się na nim przycisk "Importuj...". W efekcie pojawi się okno importowania metadanych (ekran poniżej). W oknie tym należy wskazać lokalizację utworzonego pliku CSV oraz kliknąć przycisk „Importuj”.
Jeżeli plik CSV zawiera więcej niż jeden opis obiektu to aplikacja poprosi o wskazanie opisu, którego dane mają zostać zaimportowane (ekran poniżej).
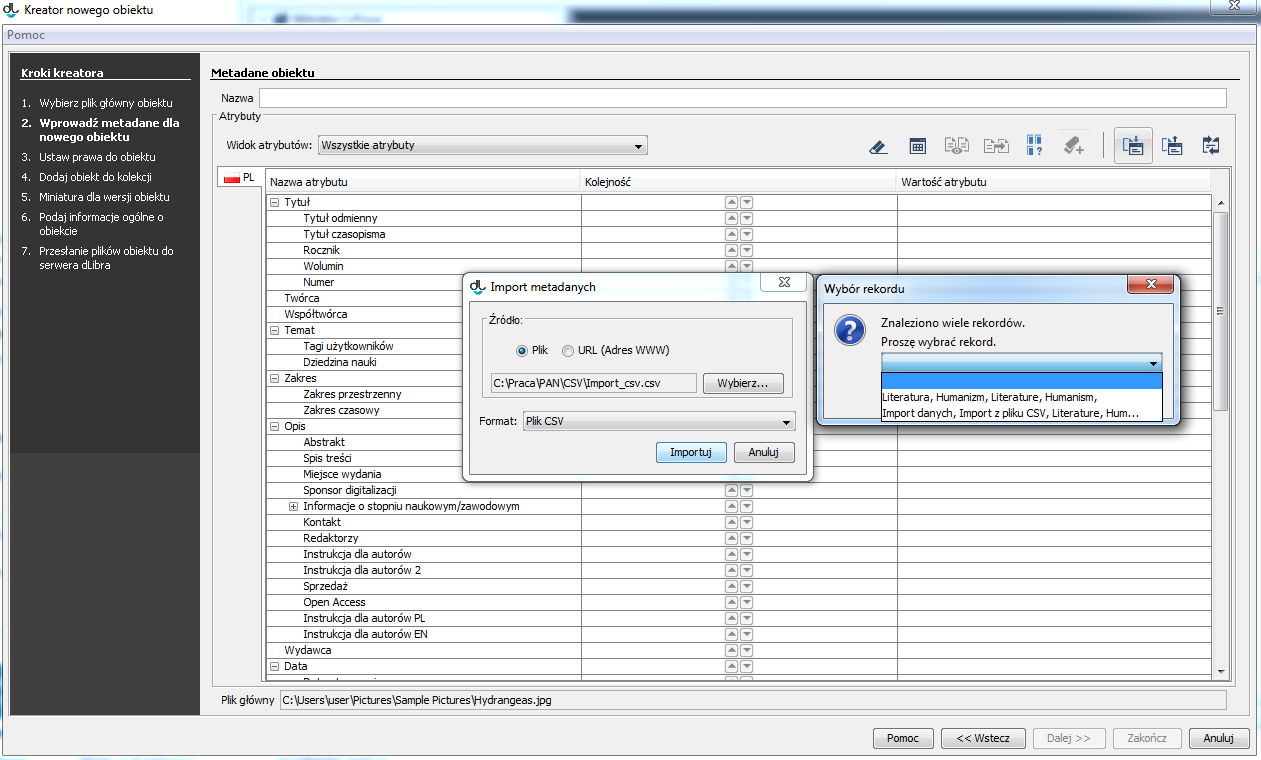
Po wskazaniu poprawnego rekordu i zatwierdzeniu wyboru metadane obiektu zostaną uzupełnione.