Architektura systemu dLibra
System dLibra jest systemem wielowarstwowym o architekturze przedstawionej na poniższym schemacie: 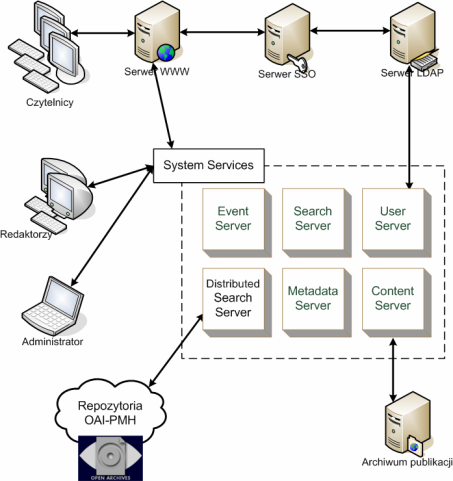
Oznaczony przerywaną linią prostokąt reprezentuje serwer systemu dLibra opisany dokładniej w dalszej części tekstu. Z serwerem komunikują się następujące komponenty architektury systemu:
- Aplikacja redaktora i administratora - osobna aplikacja wykorzystywana do zarządzania biblioteką cyfrową, do umieszczania i modyfikacji treści i metadanych dostępnych w bibliotece, etc.
- Aplikacja czytelnika - uruchomiona na serwerze WWWaplikacja, dzięki której czytelnicy mogą przeglądać oraz przeszukiwać zawartość biblioteki cyfrowej. Aplikacja WWW może do autentykacji użytkowników wykorzystywać systemy typu Single Sign-On. Aplikacja ta udostępnia również interfejs dostępowy oparty na protokole OAI-PMH.
- Panel administracyjny serwera dLibra - panel oparty o technologię Java JMX umożliwiający monitorowanie stanu serwera oraz wykonywanie operacji przewidzianych do obsługi sytuacji awaryjnych. Są to m.in. operacje takie jak odtworzenie indeksów wyszukiwawczych.
Serwer systemu dLibra
Serwer systemu dLibra składa się z szeregu współdziałających ze sobą usług sieciowych, tworzących razem w pełni funkcjonalną bibliotekę cyfrową. Usługi te to:
- Content Server - odpowiada za przechowywanie i udostępnianie treści obiektów umieszczanych w bibliotece cyfrowej. Ma możliwość automatycznego wykonywania kopii bezpieczeństwa na zewnętrzny serwer archiwum publikacji.
- Metadata Server - odpowiada za przechowywanie i udostępnianie metadanych na temat obiektów umieszczonych w bibliotece cyfrowej. Zarządza również wewnętrzną strukturą biblioteki, podziałem na katalogi, kolekcje, zestawem atrybutów, słownikami wartości atrybutów itd.
- Search Server - odpowiedzialny za indeksowanie i przeszukiwanie treści oraz metadanych na temat obiektów dostępnych w bibliotece cyfrowej.
- Distributed Search Server - odpowiedzialny za pobieranie, przechowywanie i udostępnianie metadanych na temat obiektów dostępnych w innych bibliotekach cyfrowych dostępnych poprzez protokół OAI-PMH.
- User Server - przechowuje informacje na temat użytkowników, grup użytkowników oraz uprawnień do poszczególnych publikacji. Jest wykorzystywany do autentykacji i autoryzacji przy dostępie do zasobów biblioteki cyfrowej. Może wykorzystywać zewnętrzne bazy użytkowników dostępne poprzez protokół LDAP.
- Event Server - wykorzystywany do asynchronicznej komunikacji pomiędzy pozostałymi serwerami systemu dLibra.
- System Services - usługa wykorzystywana do łączenia usług systemu dLibra w bibliotekę cyfrową oraz do autoryzacji dostępu pomiędzy usługami.
Skalowanie systemu dLibra
Każda z usług systemu dLibra może być uruchomiona na osobnym serwerze lub też usługi te mogą być łączone w grupy. Dodatkowo każda z usług systemu dLibra wymaga do swojego działania relacyjnej bazy danych. Usługi mogą współdzielić między sobą jedno konto bazy danych, ale mogą też korzystać z odrębnych baz danych uruchomionych na osobnych serwerach.
Podstawowy wariant konfiguracji systemu dLibra to wszystkie usługi uruchamiane na pojedynczym serwerze jako jedna grupa. W przypadku potrzeby rozbudowy biblioteki cyfrowej istnieje możliwość przenoszenia poszczególnych komponentów systemu na odrębne serwery. Obecnie maksymalny stopień rozbicia systemu dLibra oznacza uruchomienie tego systemu na piętnastu serwerach: 7 x serwer bazy danych dla poszczególnych usług, 7 x serwer dla poszczególnych usług systemu dLibra, 1 x serwer na aplikację czytelnika. Takie rozbicie jest oczywiście uzasadnione tylko w skrajnych prrzypadkach. Poniżej opisano przykłady przeskalowania systemu dLibra na 2 oraz 3 serwery.
Dwa serwery
Pierwszy serwer: Następujące usługi systemu dLibra: Metadata Server, User Server, Event Server, Distributed Search Server, System Services, Serwer WWW z aplikacją czytelnika, Baza danych współdzielona przez wszystkie usługi pierwszego serwera
Drugi serwer: Następujące usługi systemu dLibra: Search Server, Content Server, Baza danych współdzielona przez wszystkie usługi drugiego serwera. Takie podejście pozwala wydzielić część systemu dLibra zajmującą się przechowywaniem i indeksowaniem treści. Jest to część, która generuje duże obciążenie serwera w momencie dodawania nowych publikacji do biblioteki cyfrowej. Dzięki temu w momencie maksymalnych obciążeń drugiego serwera, związanych z analizą zawartości obiektów cyfrowych, nadal możliwe jest funkcjonowanie aplikacji czytelnika oraz praca użytkowników aplikacji administratora oraz redaktora, gdyż wszystkie metadane wraz ze stosownymi usługami znajdują się na pierwszym serwerze.
Trzy serwery
Pierwszy serwer: Następujące usługi systemu dLibra: Metadata Server, User Server, Event Server, Distributed Search Server, System Services, Baza danych współdzielona przez wszystkie usługi pierwszego serwera
Drugi serwer: Następujące usługi systemu dLibra: Search Server, Content Server, Baza danych współdzielona przez wszystkie usługi drugiego serwera
Trzeci serwer: Serwer WWW z aplikacją czytelnika. Takie podejście dodatkowo odseparowuje aplikację czytelnika, która może powodować okresowe większe obciążenia w przypadku zwiększonego ruchu czytelników. Dzięki wbudowanemu w aplikację czytelnika mechanizmowi cache, jest ona stosunkowo niezależna od usług systemu dLibra, a więc takie przeskalowanie systemu umożliwia rozłożenie na dwa serwery (odpowiednio pierwszy i trzeci) obciążenia związanego z pracą użytkowników aplikacji redaktora i administratora oraz obciążenia związanego z obsługą żądań czytelników. Podobnie jak w poprzednim scenariuszu, drugi serwer odpowiedzialny jest za przechowywanie i przetwarzanie udostępnianych treści cyfrowych.