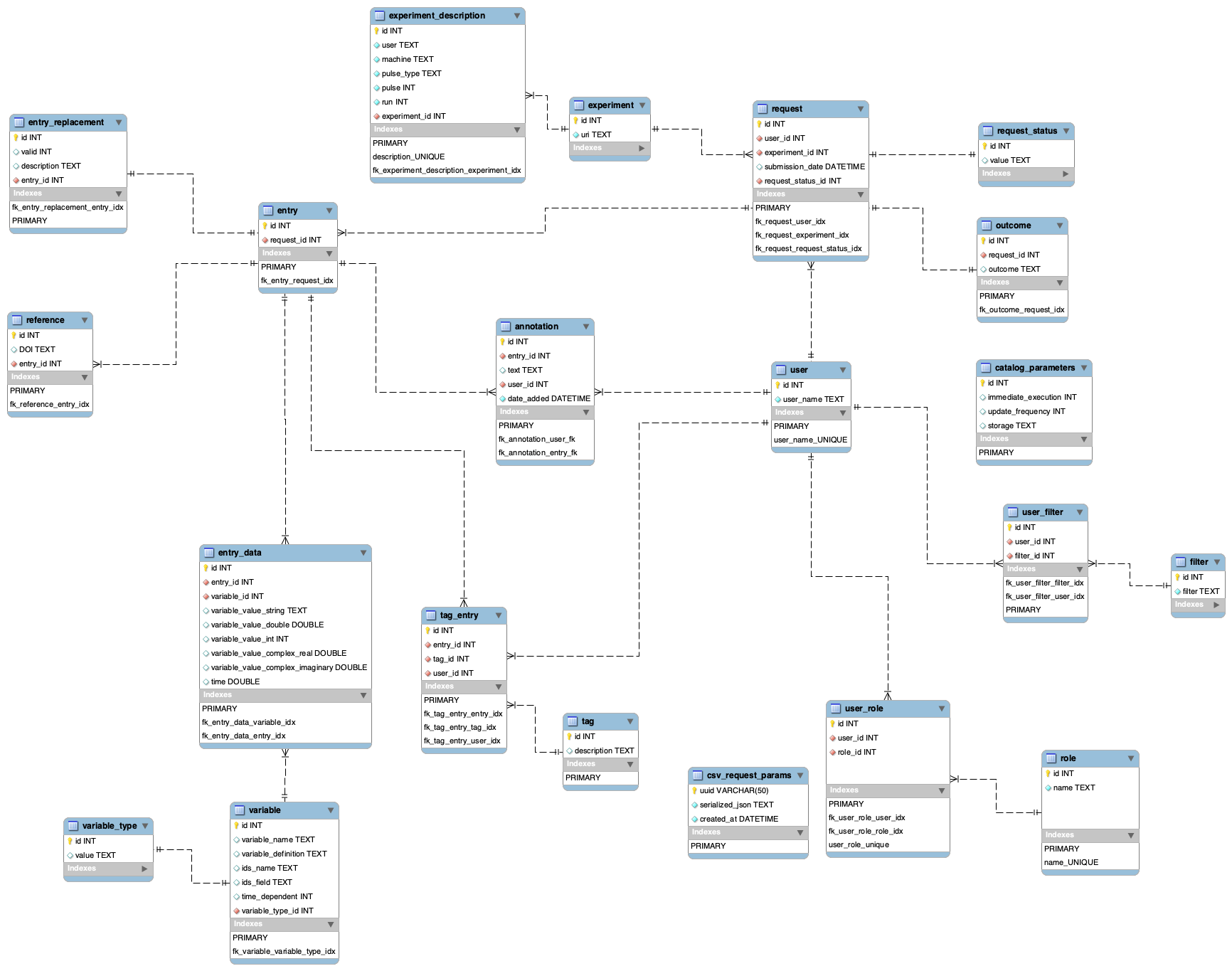
...
- complex types are stored as real and imaginary
- variables contain "
ids" in in the name instead of "ofcpo"
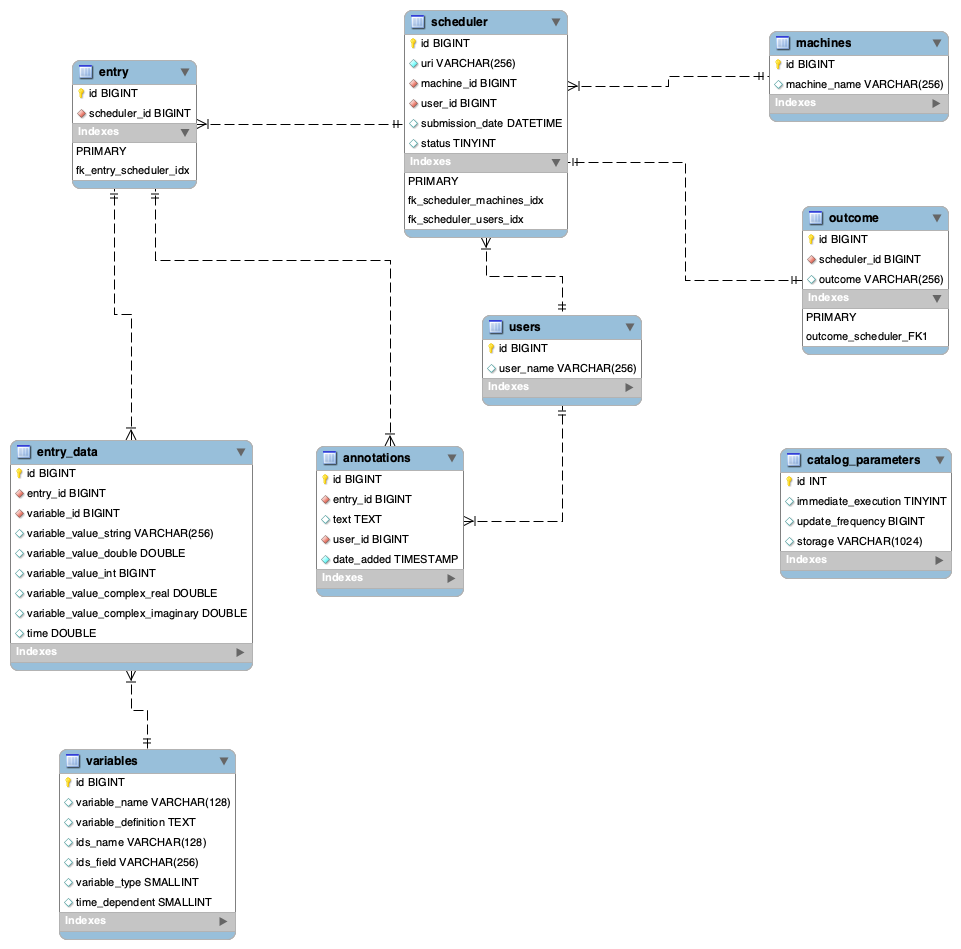
Refined schema (step 3)
Experiment database
- scheduler table is now called request
- all the plural names of tables were changed to singular ones
- all the indexes are now unified (naming convention is the same across all the indexes)
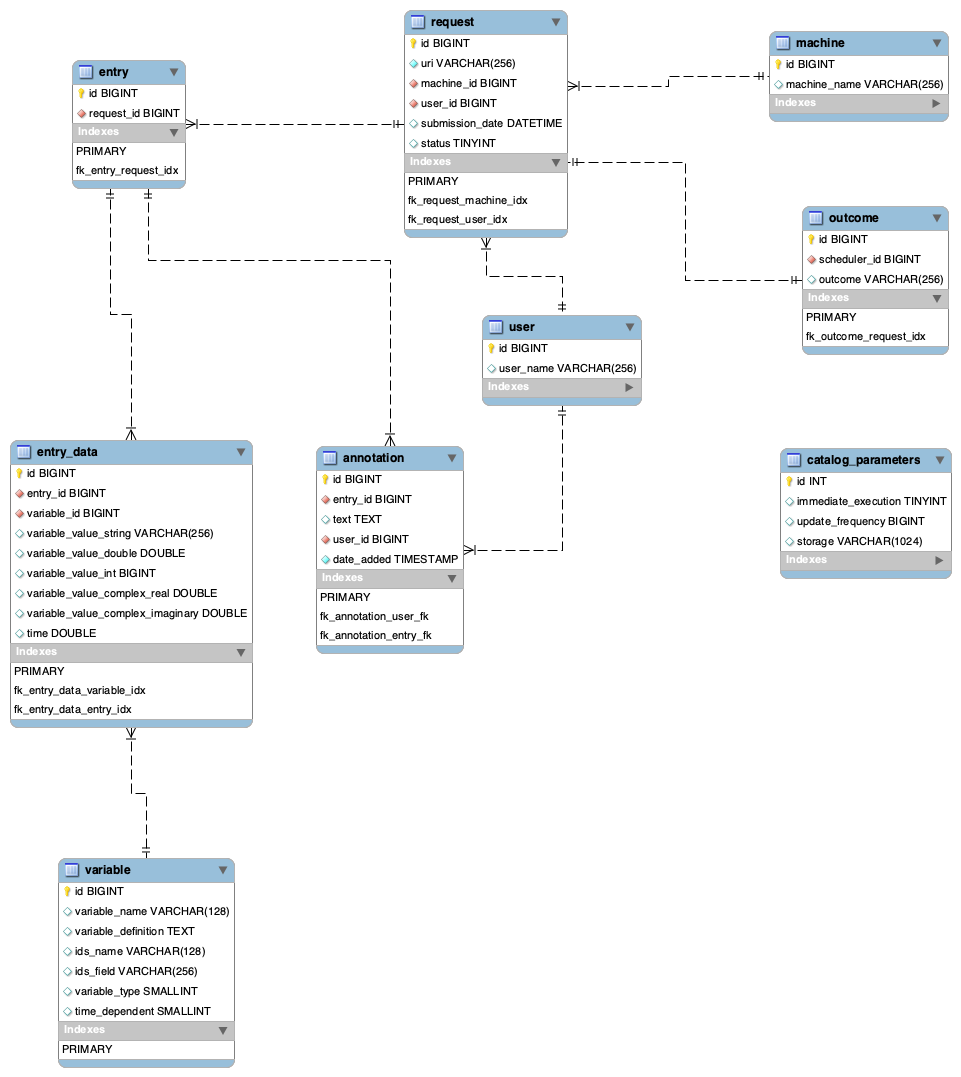
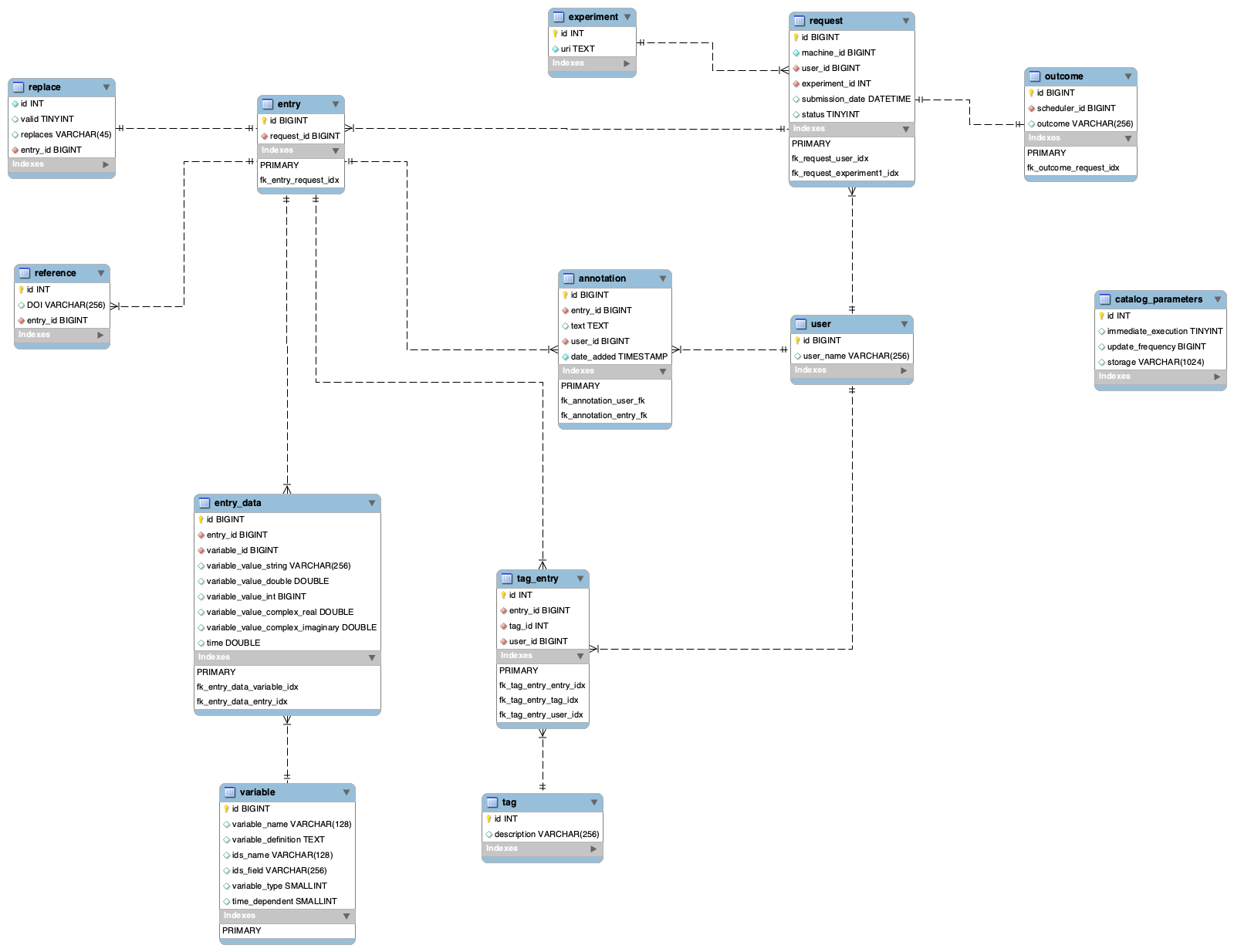
Refined schema (step 4)
Experiment database
- request table no longer holds URI for the data entry
- there is a new table: experiment. This table contains location of data we are working with. As we may have multiple requests for a single experiment (e.g. update of the data) I want to keep URI in separate table.
- entry table is now linked with request - this way it points to the experiment (via request)
- There is a new table: replace - this table will contain information for tracking additional info (as described in Proposal on Metadata Schema Standardisation and Mapping Existing Schemas)
- There is a new table: reference - this table will allow to store multiple DOI (maybe something else) related to a particular entry
- There is a new table: tag - this table will contain all the tags defined by users
- There is a new table: tag_entry - this table will contain all the links between: user, tag and entry; this way it will be possible to track who has tagged entry with given tag
- Removed: machine table is no longer here. Do we really need it?
Refined schema (step 5)
Experiment database
- auto increment for all ID fields in database
- further unification of fields (all primary keys and foreign keys are represented solely by INT)
- further cleaning of indexes
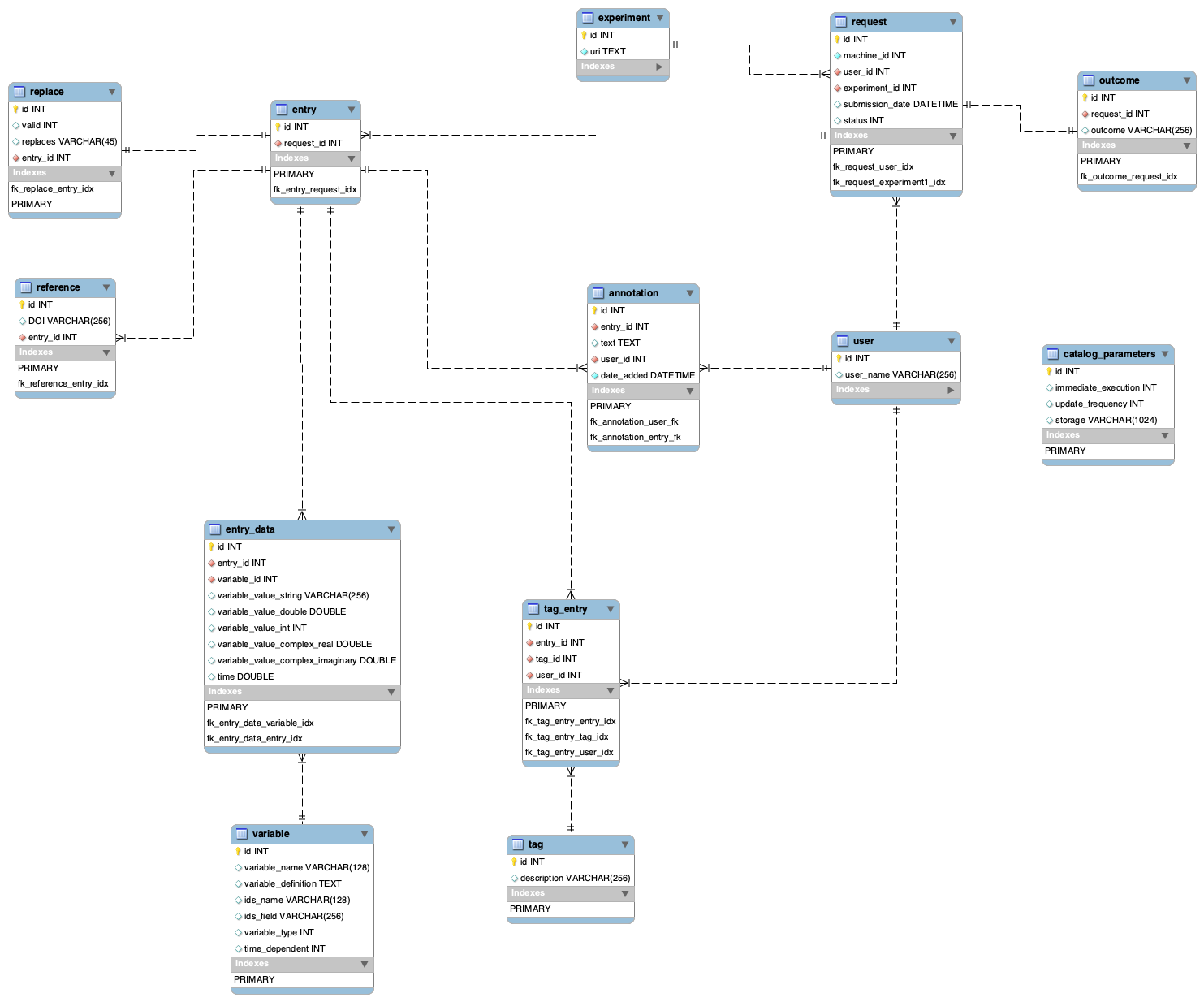
Refined schema (step 6)
Experiment database
- all text fields are now represented by VARCHAR (it's still a subject to change)
- using TEXT as type of column lead to strange issues in some of the SQL engines (e.g. H2)
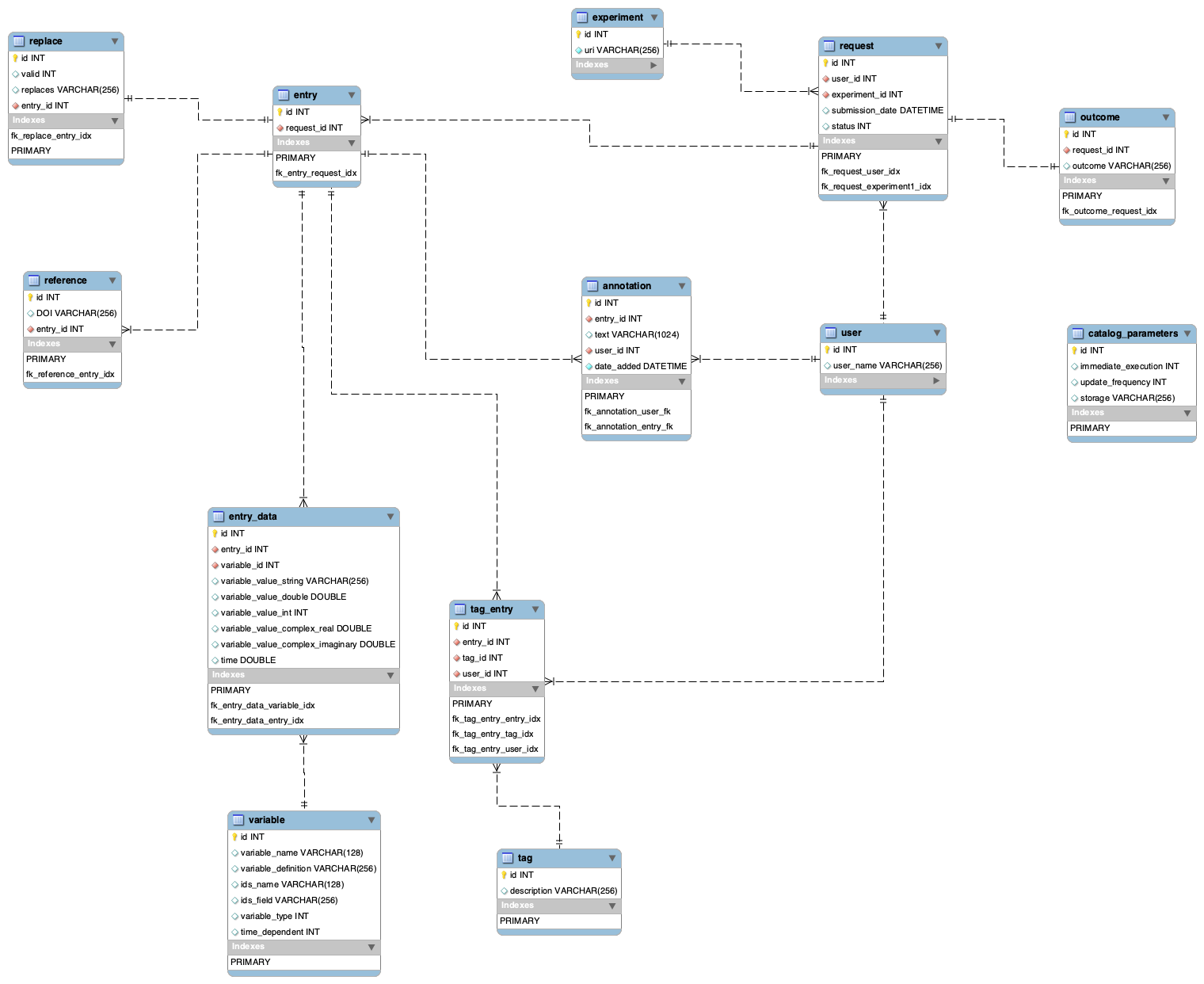
Refined schema (step 7)
Experiment database
- table replace was renamed to entry_replacement - by accident, we have used reserved word
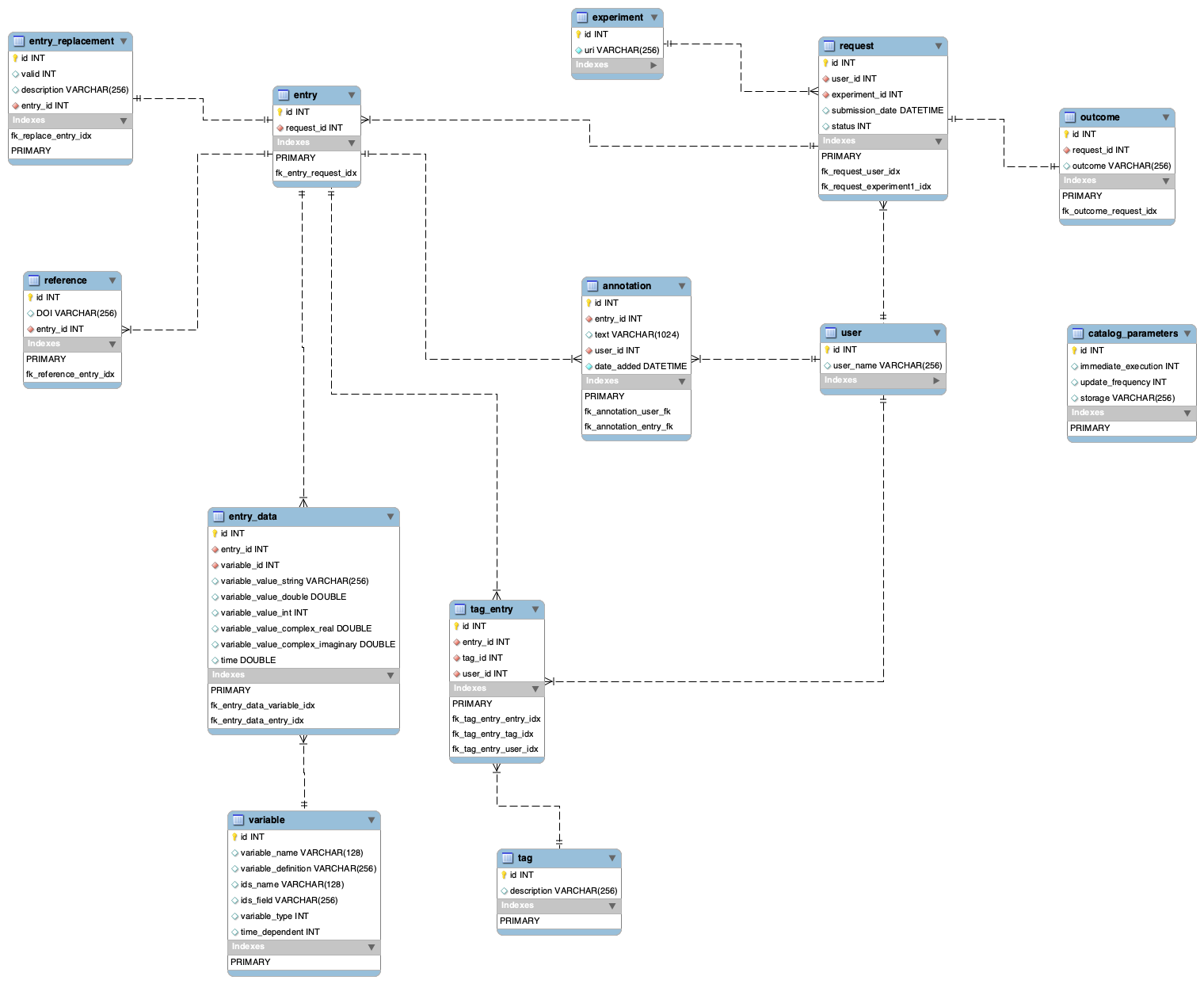
Refined schema (step 8)
| Anchor | ||||
|---|---|---|---|---|
|
Experiment database
- There is a new table:
variable_type- it describes possible types of the variables - Inside variable table, there is no longer
variable_typecolumn. Instead there is a foreign key (variable_type_id) that points atvariable_type.id - There is a new table:
request_status- it describes possible statues of the request - Inside request table there is no longer
statuscolumn - instead there is a foreign key (request_status_id) that points atrequest_status.id
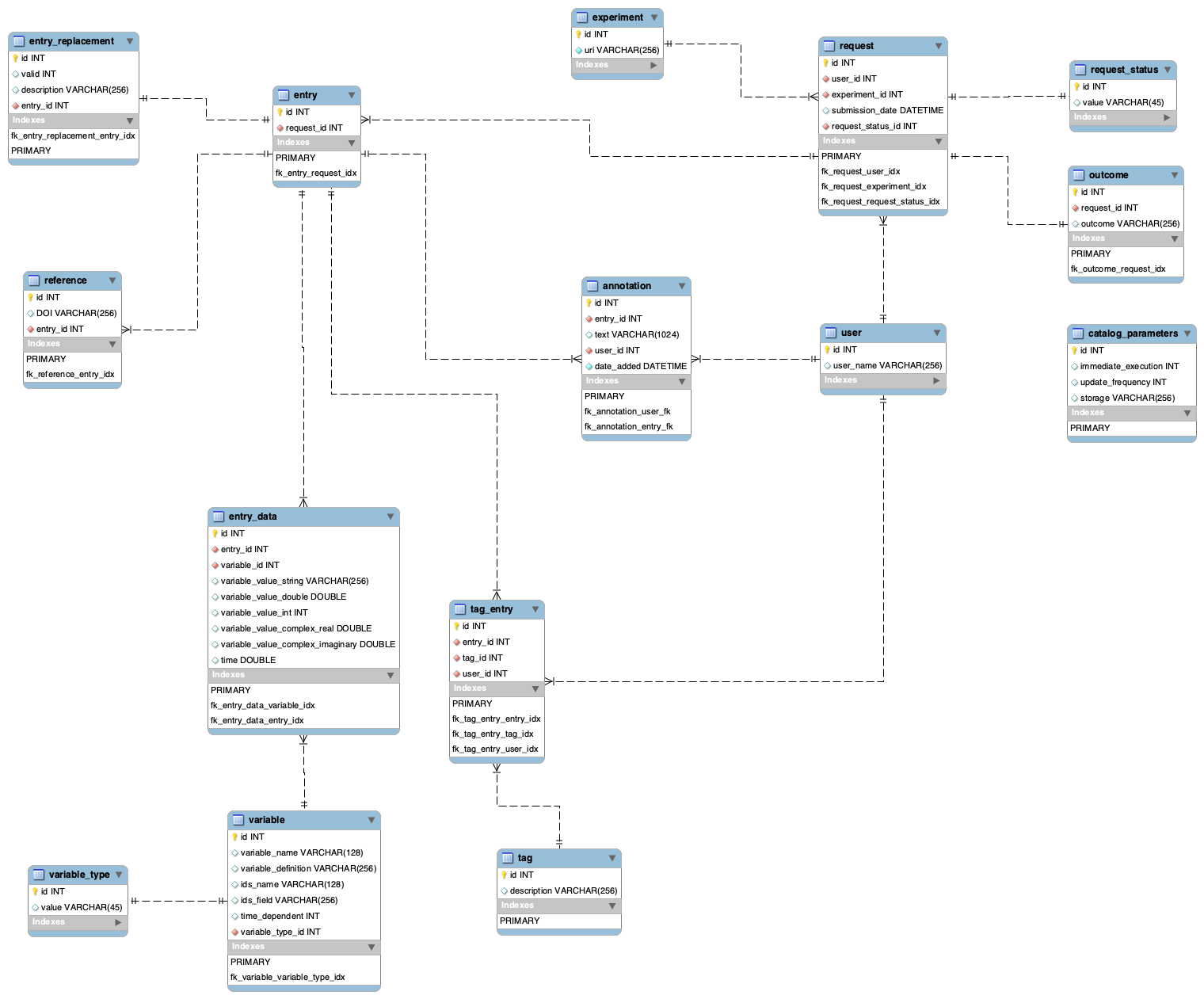
Refined schema (step 9)
Filter table
- There is a new table: filter - it allows to store custom user filters
- There is a new table: user_filter - it allows to link filter with user; it is possible to share filter between different user - this is why filters require linking table between user and filter
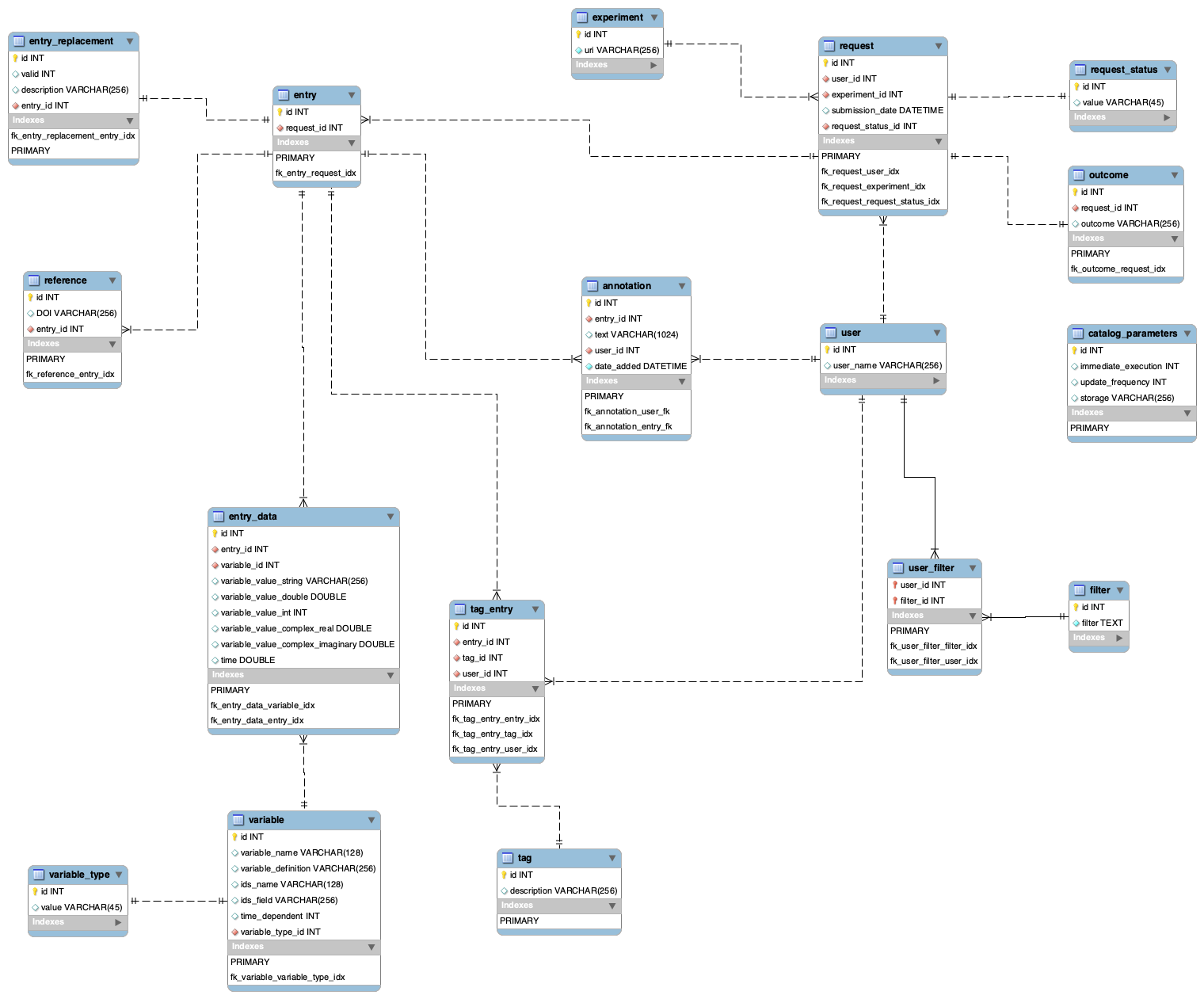
Refined schema (step 10)
user_filter
- There are fixes inside user_filter table
- There is a new explicit ID column
- relations are non-identifying (user - user_filter - filter)
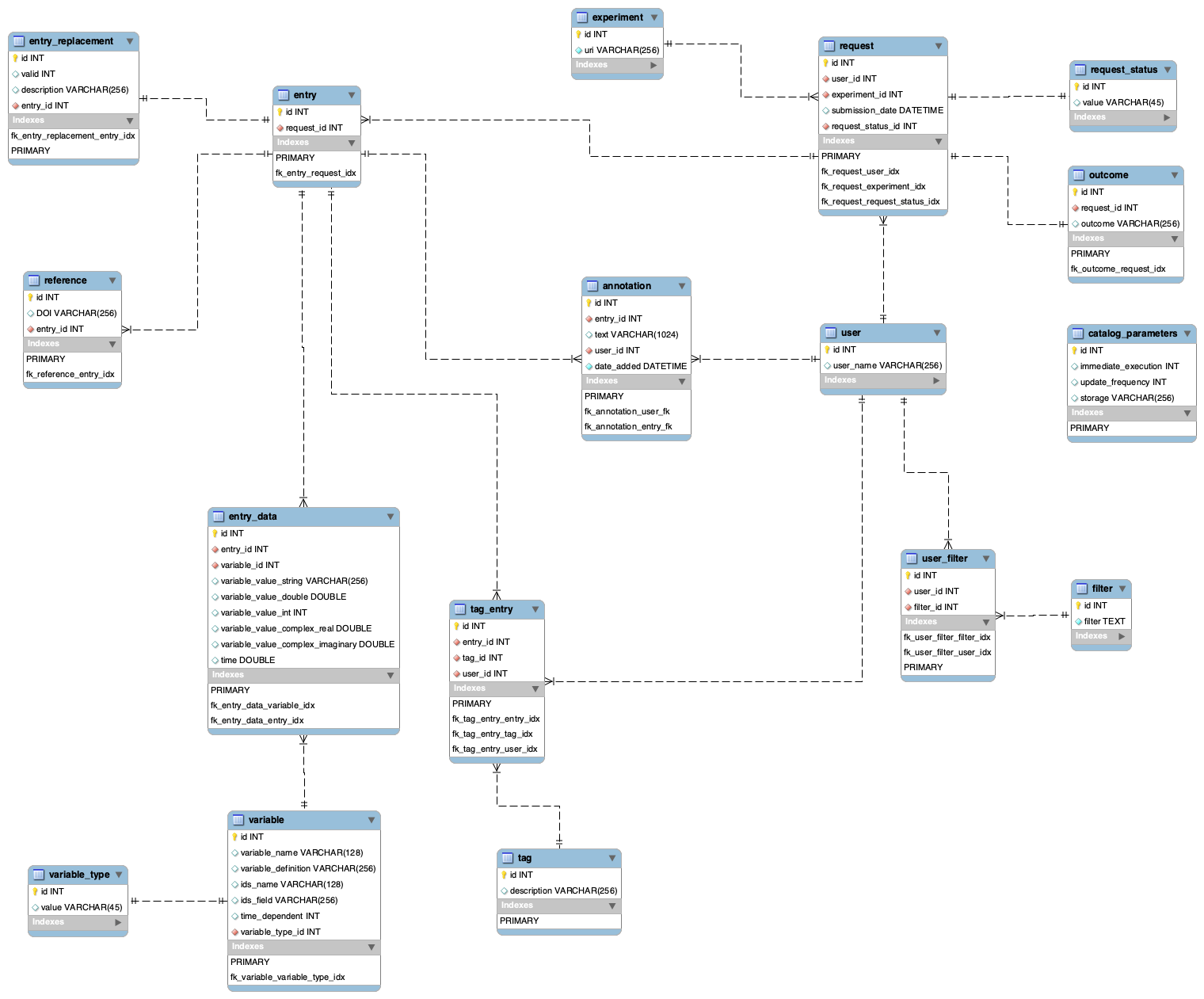
Refined schema (step 11)
experiment_description
- experiment_description is a table that allows to uniquely identify experiments based on dataset_description IDS
- https://trello.com/c/8lZbmTBg
VARCHAR to TEXT
- all text fields are now represented by TEXT fields